





前言
Gemma 4 是 Google DeepMind 推出的最新开源大语言模型,基于 Gemini 3 研究成果打造,在有限参数下实现了前所未有的智能水平。本文将详细介绍如何在各类设备上本地部署 Gemma 4。
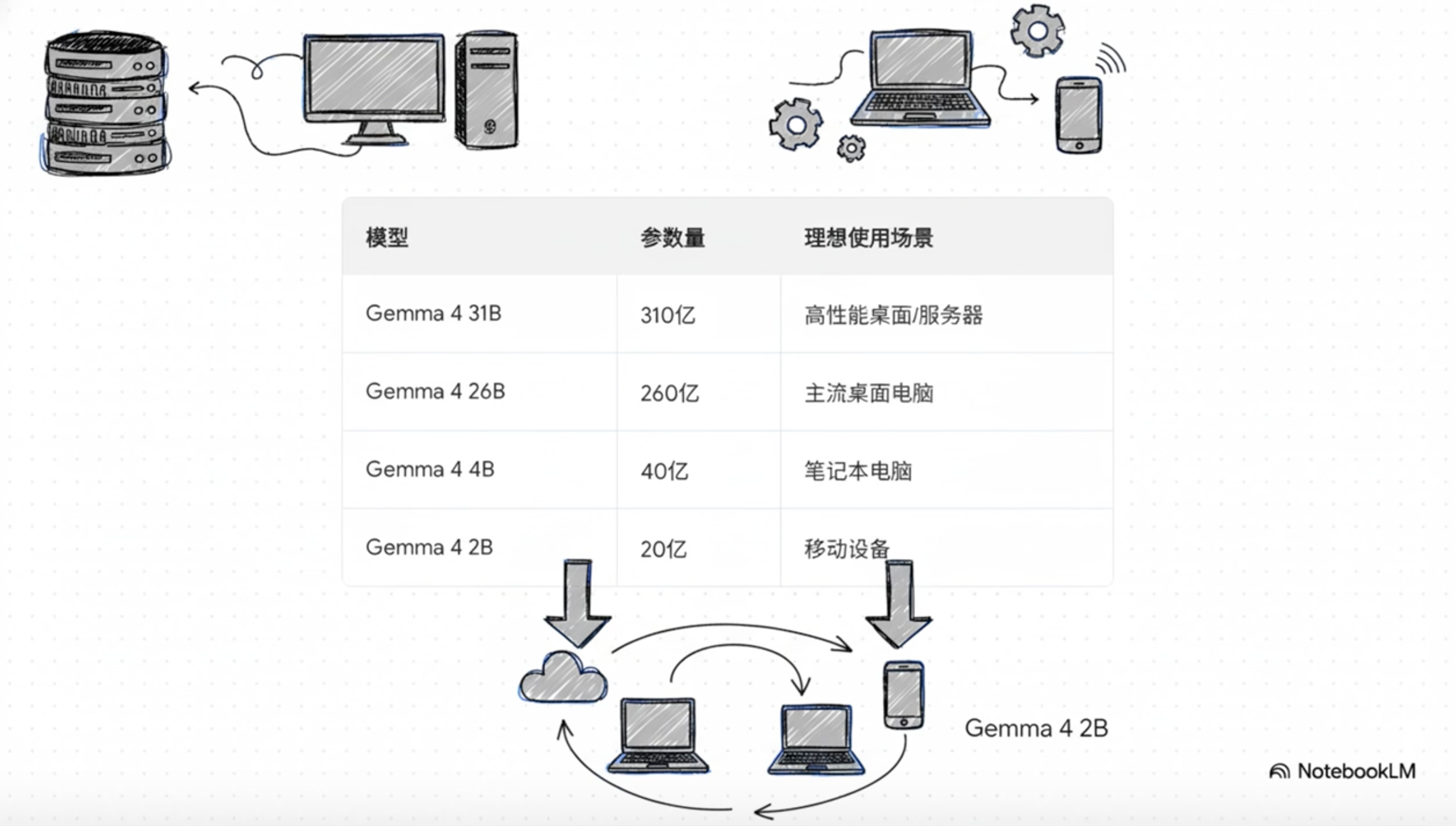
📊 Gemma 4 模型家族
Gemma 4 提供多个参数规模的版本,适应不同硬件条件:
| 模型 | 参数量 | 适用场景 |
|---|---|---|
| Gemma 4 31B | 31B | 高性能桌面/服务器 |
| Gemma 4 26B | 26B | 主流桌面电脑 |
| Gemma 4 4B (E4B) | 4B | 笔记本电脑/高端手机 |
| Gemma 4 2B (E2B) | 2B | 移动设备/嵌入式设备 |
核心特性
- Agentic Workflows:原生支持函数调用,可构建自主规划、导航应用的 AI 代理
- 多模态推理:支持音频和视觉理解
- 140 种语言:超越翻译,理解文化语境
- 微调支持:支持使用主流框架进行定制化训练
基准测试表现
| 基准测试 | Gemma 4 31B | Gemma 4 26B | Gemma 4 4B | Gemma 3 27B |
|---|---|---|---|---|
| Arena AI (文本) | 1441 | 1365 | - | - |
| MMMLU 多语言 | 85.2% | 82.6% | 69.4% | 67.6% |
| MMMU Pro 多模态 | 76.9% | 73.8% | 52.6% | 49.7% |
| AIME 2026 数学 | 89.2% | 88.3% | 42.5% | 20.8% |
| LiveCodeBench 编程 | 80.0% | 77.1% | 52.0% | 29.1% |
| τ2-bench 工具使用 | 86.4% | 85.5% | 57.5% | 6.6% |
🖥️ 电脑端部署
Mac 系统部署
方案一:Ollama(推荐⭐)
ollama run gemma4:e4b
方案二:LM Studio
- 从 lmstudio.ai 下载 macOS 版本
- 搜索 “Gemma 4” 下载模型
- 选择量化版本(推荐 Q4_K_M 平衡性能与内存)
方案三:llama.cpp 本地编译
# 克隆 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# 编译
make -j$(nproc)
# 转换模型为 GGUF 格式(需要先下载原始模型)
python3 convert.py /path/to/gemma-4b-model/
# 运行推理
./main -m gemma-4b-q4.gguf -n 256
Windows 系统部署
方案一:LM Studio(最简单)
- 下载 LM Studio for Windows
- 安装后打开,搜索 “Gemma 4”
- 选择合适的量化版本下载
- 点击加载即可使用本地聊天界面
方案二:Ollama for Windows
# 通过 PowerShell 安装
winget install Ollama.Ollama
# 启动服务
ollama serve
方案三:WSL2 + llama.cpp
如果你有英伟达显卡,推荐使用 WSL2:
# 安装 WSL2 和 CUDA 支持
wsl --install
# 在 WSL2 中安装 llama.cpp CUDA 版本
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make LLAMA_CUBLAS=1 -j$(nproc)
Linux 系统部署
服务器部署(高并发场景)
# 安装 Python 依赖
pip install torch transformers accelerate
# 使用 Hugging Face Transformers
python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("google/gemma-4b")
>>> tokenizer = AutoTokenizer.from_pretrained("google/gemma-4b")
本地桌面部署
参考 Mac/Linux 的 llama.cpp 方案,编译支持 CUDA 的版本以获得 GPU 加速。
📱 移动端部署
Android 部署
方案一:MLC LLM(推荐)
MLC (Machine Learning Compilation) LLM 是由 TVM 团队开发的跨平台推理引擎,支持在 Android 上高效运行大语言模型:
-
使用预编译应用:
- 下载 MLC Chat Google Play 版本
- 在应用内搜索 “Gemma 4” 并下载
-
自行编译(高级用户):
# 克隆 MLC-LLM
git clone https://github.com/mlc-ai/mlc-llm.git
cd mlc-llm
# 参考官方文档交叉编译 Android 版本
# 需要 Android NDK
方案二:Gemma.cpp Android 移植
Google 官方提供了高效的 C++ 推理实现,可以编译为 Android 可执行文件:
# 下载官方 Gemma.cpp
git clone https://github.com/google/gemma.cpp.git
# 需要使用 Android NDK 交叉编译
方案三:Google AI Edge
Google 提供了 AI Edge 生态系统,支持将 Gemma 模型转换为高效的移动端格式:
- 使用 Google AI Edge 工具链
- 转换为 LiteRT 格式
- 在 Android 上通过 ML Kit 或 TensorFlow Lite 部署
iOS 部署
方案一:MLC Chat iOS
- 从 App Store 下载 MLC Chat
- 添加 Gemma 4 模型
方案二:llama.cpp iOS 移植
在 Mac 上使用 Xcode 将 llama.cpp 编译为 iOS 应用:
# 需要 Xcode 和 iOS SDK
# 参考 llama.cpp 官方 iOS 编译指南
方案三:Core ML(苹果生态最优解)
Google 提供了 Core ML 格式的 Gemma 模型,可以利用苹果神经网络引擎获得极致性能:
- 下载 Core ML 格式模型(需从 Google 官方获取)
- 使用 Xcode 集成到你的应用中
- 充分利用苹果芯片的 Neural Engine
☁️ API 方式部署(适合开发者)
如果你不想本地运行,也可以使用 Google AI Studio 的 API:
Google AI Studio API
# 使用 Google GenAI SDK
pip install google-genai
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents="Explain量子计算 in simple terms"
)
print(response.text)
注意:Gemma 4 的 API 服务可能需要申请访问权限。
💡 硬件需求参考
| 模型 | 最低内存 | 推荐内存 | GPU 要求 |
|---|---|---|---|
| Gemma 4 2B | 4GB | 8GB | 可选 |
| Gemma 4 4B | 8GB | 16GB | 推荐 |
| Gemma 4 26B | 32GB | 64GB | 强烈推荐 |
| Gemma 4 31B | 48GB | 64GB+ | 必须 |
⚡ 性能优化技巧
- 量化版本:使用 Q4_K_M 或 Q5_K_S 量化可在保持 95% 性能的同时减少 60% 内存占用
- GPU 加速:确保有 CUDA 支持(NVIDIA 显卡)或 Metal 支持(苹果芯片)
- CPU 推断:仅使用 CPU 时,建议选择 2B 或 4B 版本
- KV Cache 量化:可以显著降低内存占用
📥 下载模型
- Hugging Face: google/gemma-4
- Kaggle: Gemma 4 Models
- Google AI Edge: ai.google/ai-edge
🔄 总结
| 设备类型 | 推荐方案 |
|---|---|
| Mac (Apple Silicon) | LM Studio / llama.cpp (Metal) |
| Windows (NVIDIA) | LM Studio / llama.cpp (CUDA) |
| Linux 服务器 | llama.cpp + CUDA / Transformers |
| Android | MLC Chat / Google AI Edge |
| iOS | MLC Chat / Core ML |
Gemma 4 作为 Google 最强的开源模型,在移动端和桌面端都有不错的部署选项。随着社区生态的完善,预计会有更多便捷的部署方案出现。建议持续关注官方更新和社区动态。
本文基于 2026 年 4 月 Gemma 4 官方发布信息整理。


评论区